In the previous post we saw the basics of hashmap, structure of the node stored in hashmap, various concepts related to hashmap, hashmap available constructors and a code which demonstrates the use of various functions using different hashmap constructors. In this post I will discuss the internal implementation of hashmap along with how it looks internally while debugging.
Prerequisites:
Basic knowledge of hashmap is required.
To get an idea of basics of hashmap, refer Basics of HashMap in Java.
Explanation:
Consider a hashmap with key and value data type as String and Integer respectively. with default initial capacity of 16 and default load factor 0.75.
Map<String, Integer> map = new HashMap<String, Integer>();
The above code will create an empty hashmap with table as null and default load factor 0.75 as below,

Adding a key-value pair to the hashmap, adds the new node to the index/bucket calculated using the hash function and remaining buckets are empty. The size of the hashmap changes to 1 and threshold is calculated as 0.75*16=12.
map.put("hetal", 1);
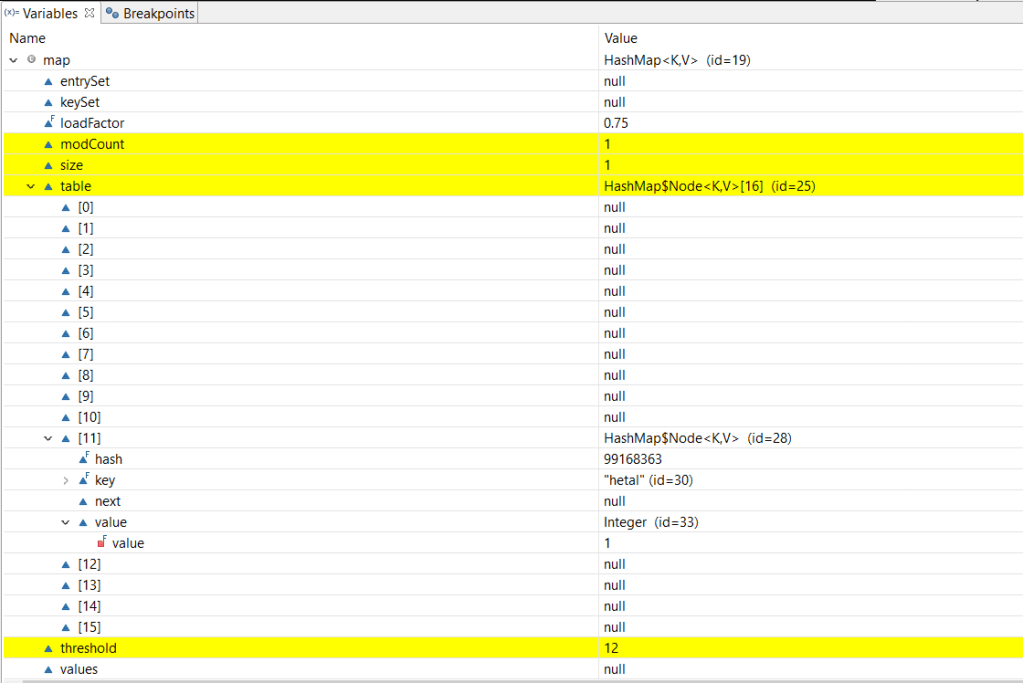
The node stored at bucket [11] as shown in above image, contains the hash code 99168363, the key “hetal”, the value 1 and the reference to the next node in the same bucket which is null since we do not have any other node stored in the same bucket.
The put method calculates the hash code and the index where the key-value pair will be stored. In this case it got derived as 11.
Note: Hashmap node stored at bucket [11] i.e. HashMap$Node<K,V> indicates that Node<K,V> is an inner class of HashMap class. And HashMap$Node<K,V>[16] at table indicates that the hash map has capacity of 16 buckets.
Now if another key-value pair is put in the hashmap, same process is followed of creating a hash code and the index/bucket where the node will be stored.
map.put("rachh", 2);

As shown in the above image, the new key-value pair is stored at index 0. The hash code generated is 108271200, key is “rachh”, value is 2 and the next reference is null because there is no other node stored at that bucket in the hashmap.
What happens when a hash collision occurs?
Consider below code where two more key-value pairs are added to the hashmap.
map.put("FB", 3);
map.put("Ea", 4);
Now the hashmap table looks as below,

In the above image, the node at bucket [12] (highlighted in blue) has key-value pair “FB”-3 stored which has hash code 2236 and next reference as another node with hash 2236, key as “Ea” and value as 4. Hence, when a hash collision occurs i.e. when two more more keys produce the same hash code (in this case it is 2236) which eventually will produce the same index/bucket where they both will be stored, the nodes get stored as a linked list in the bucket in the hash map where one node has a reference to another node in the “next” reference variable (highlighted in yellow). Both the nodes with keys “FB” and “Ea” gets stored at bucket [12] in the hashmap.

What happens when two key-value pairs with same keys are put in hashmap?
Suppose below key-value pairs are put in hashmap with same key “hetal” but values are different.
map.put("hetal", 1);
The key-value pair gets stored in bucket [11] in the hashmap as shown below,

Now if we add another key-value pair with same key “hetal”, then the key-value pair with the same key gets updated i.e. the value gets updated with new key-value pair’s value as shown below,
map.put("hetal", 2);

As shown in the image above, the node with key “hetal” gets updated with value as 2 (which was 1 before).
What happens when the key is null?
Suppose we put below key-value pair in the hashmap,
map.put("null", 1);
If the key entered is null then the hash value generated will always be 0 and the node will be stored at bucket [0].

In the above image as shown, the node gets stored at bucket [0] with hash as 0, key as null and value as 1.
What happens when the size of the hashmap reaches the threshold value?
Consider below 13 key value pairs entered in the hashmap. We also know from the previous post that the default load factor of the hashmap is 0.75 and the default capacity is 16 which gives a threshold value of 12. Also, we saw that when the size of the hashmap reaches the threshold value re-hashing takes place. Re-hashing is a process in which the capacity of the hashmap is doubled and the threshold value is calculated again with the new capacity of the hashmap.
map.put("a", 1);
map.put("b", 2);
map.put("c", 3);
map.put("d", 4);
map.put("e", 5);
map.put("f", 6);
map.put("g", 7);
map.put("h", 8);
map.put("i", 9);
map.put("j", 10);
map.put("k", 11);
map.put("l", 12);
map.put("m", 13); //13th node
The capacity of the hashmap remains the same i.e. 16 unless the threshold value 12 is not reached.

As shown in above image, the capacity remains 16 until 13th node is added.Once more than 12 nodes are put in the hashmap i.e. when 13th node is put, the capacity doubles to 32 and new threshold value will be 0.75*32 = 24 as shown in below image,

As you can see in above image the size of the table becomes to 32 meaning it can store upto 32 buckets and the threshold value becomes 24.
I hope this post helped you to understand the internal working of hashmap. Please provide your feedback in the below comment section. Thank you so much.
